A review of the "tjr_simple_earley" code
Repository is here: https://github.com/tomjridge/tjr_simple_earley
This commentary refers to commit 0dc99ad
ocamldoc is available
OCaml source code in src/
Main file: tjr_simple_earley.ml https://github.com/tomjridge/tjr_simple_earley/blob/master/src/tjr_simple_earley.ml
Config and Misc are utility modules.Earley_intf has the main interfaces. Earley_base is the first implementation.
General comments about the code: In order to run fast, we want every representation (of terminal, nonterminal, symbol, list of symbols, etc) to be an integer. Thus, we try to keep everything independent of the exact representation. Unfortunately this code was written about 5 years ago and I think I could do a better job today.
Earley_intf
https://github.com/tomjridge/tjr_simple_earley/blob/master/src/earley_intf.ml
Starts with a general input type.
Introduces nonterminals nt and terminals tm (symbols).
A (simple) grammar is a function from nt to a list of (a list of symbols).
A variation on this allows the grammar to depend on the input and parse position. (This is rather unusual - please ignore.)
A terminal input matcher describes how a terminal matches the input at a given position. It generalizes the usual notion of terminal (a character, or the empty string). Given a position in the input, the return value is a list of all possible spans that can be parsed by that terminal at that position.
The parse_result type should be ignored for now.
Then we meet some signatures.
REQUIRED is a general list of the functions we need.
nt_item is something that looks like: X -> i, as . k bs , where as and bs are lists of symbols. It represents a point in the parse from position i, for nonterminal X, where the rule is of the form (X -> as, bs), and we have progressed to position k by parsing as.
Simple_items takes basic nonterminal and terminal types and constructs something that fulfills the REQUIRED interface (presumably - this isn't clear from the code :( )
Mt_full seems to contain a lot of duplication; sym_list is held abstract; nt_item is revealed (the as part is omitted because actually it is not relevant).
Mt_full contains the "items" that we work with. A sym_item represents a completed parse of a symbol from position i to j. A sym_at_k represents a work item: we need to try to parse a symbol at position k. Finally, all items are either nt_items, or sym_items or sym_at_k items
Mt_abstract keeps nt_item abstract.
Comments: There is a lot of duplication. This code was written many years ago (I would write it much differently now). It looks like there was some use of ppx_include, but the comment states that this rarely worked with newer OCaml versions.
Overall, this interface file has too much duplication.
Earley_base
More duplication in the REQUIRED_BY_BASE module type (sigh). This also includes extra components: nt_item_set (presumably a set of nt_item). There are also additional types for "bitms_lt_k" (blocked items at positions less than k... k is the "current" position), todo_gt_k (sets of nt_items that we need to process in the future at some position); bitms_at_k (blocked items at the current position), ixk_done (completed nonterminal parses of the form (i,X,k) ie between position i and k), ktjs (terminal parses of the form (k,t,j) ie for terminal t between position k and j), and various other functions.
Looking back, this is sort-of OK, but not very readable.
Then there is a Make functor for the actual implementation. The state type is declared inside the functor. A monad is declared to represent a "state passing" computation. A record of "atomic_operations" is described. (Really, this is all a bit hairy to understand on the fly.)
Then the Internal2 modules gives the implementation of Earley (at least, an Earley-like algorithm) in terms of the atomic operations.
There is an attempt to document what the code is doing at each step. I think at the time I favoured being able to see the entire algorithm, with all the cases, in one page.
In this "run_earley" function, there is usage of a "mark" function. This is for performance profiling (nothing to do with the behaviour of the algorithm itself).
The use of the monad is so that the code can be verified. At the time I wanted all my code to (at least in theory) exist in Isabelle and also in OCaml. I'm not so sure now that the use of the monad is worth it, compared with "immediate" OCaml (ie mutating state).
Anyway, the final type of the run_earley function is somewhat understandable:

Note that the monad is a state passing monad, so the ultimate return type "unit m" means that if we provide an initial state, we eventually get the result state from the parse.
The file ends with some horrible exporting.
Earley_simple
The next module in sequence is Earley_simple, which provides a somewhat efficient implementation of Earley_base:
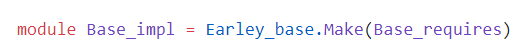
Actually, the main data structures seem to use purely functional sets and maps. So this will not be as fast as an imperative implementation. But at least it is purely functional (although quite what this brings to Earley parsing is not so clear... the possibility to perform partial parses and maybe resume a parse from an intermediate state perhaps).
Earley_simple is parameterized over the types for nonterminal and terminal. These are instantiated in the main Tjr_simple_earley module:

Obviously strings are not so efficient. But there were various other inefficiencies I wanted to remove as well.
Earley_unstaged
Earley parsing is typically "staged" (bad term) in that examines the input at successive positions (ie never going back to re-examine input that has already been consumed). Earley_unstaged is a version of the parsing algorithm that doesn't operate like this - at any point it may go back and re-examine the input at a given position etc. The advantage is that the algorithm is simpler, and that it may be possible to implement various nice features with an unstaged version of the algorithm. The cost is that it is probably slower than the traditional staged version.
From the implementation state type, Hashtables are being used to implement the main data structures. So the code is no longer functional, but should be faster. The implementation makes use of Earley_spec:

Earley_spec
This module contains a very simple implementation of an Earley-like algorithm, suitable for use as a "specification".

As can be seen, there is a simple match over the type of the item, and the rest of the code is almost trivial. This "spec" is used as the basis for the Earley_unstaged implementation. It is also used (with very simple implementations of datastructures etc.) as the reference spec against which the other implementations are compared.
Examples

The details of the rest of the code are almost irrelevant - they are what they are in order to make this grammar definition possible.
The corresponding example with actions is:

Which is also pretty good I think. Note that the example is highly ambiguous - there will be a huge number of different parse trees for a relatively small input - but it is still possible to run actions if you memoize the results for each subtree of the parse tree, and if the overall results (after applying the actions) are not too numerous (here, whatever parse tree is used, the result of applying the actions is always the same). However, I don't know if this version of the code actually does this - a quick glance suggests it doesn't.
Comments
Post a Comment